



This post is the first part of the series about Sketching Algorithms. Let's first define what is meant by a sketch.
A 'sketch' is a data structure that supports a pre-defined set of queries and updates on the data stored in it while consuming substantially less amount of space (often exponentially lesser) than would be needed to store every piece of data which has been observed. Sketching algorithms are used to support such queries using sketches.
These algorithms are commonly used to solve problems in distributed systems where real-time stream processing is needed. Some examples of such use case would be counting the number of views on a video or checking whether a video has been already watched by a user. Evaluating such queries would require storage of all historic data as well as high computation time. To avoid this, sketching algorithms take a hit on accuracy and provide an approximate solution to the queries while consuming lesser space and often time.
Let's now jump into one such data structure: Bloom Filter
Bloom Filter
Bloom filter is a probabilistic data structure that is used to answer the following types of queries:
- Has the video been already seen by the user?
- Is the username available?
- Is this a malicious URL?
- Here's a link to a few more use cases for Bloom Filters
Considering the probabilistic aspect of the data structure, when asked about whether an element is present in a set, it can tell either the element is definitely not (true-negative) or maybe present (true-positive or false-positive).
Now let's dive deep into the details of storage and computation to understand its behaviour. We will now define a problem that will be used to explain the working of the bloom filter.
Problem Statement: We have a system that is responsible for the storage of user names of all users, we need to build a system that can quickly check if a particular username is already being used by some other user.
If we were to achieve this without a bloom filter, we would simply store the usernames in a database and query the DB to check if the username is present in the database. If yes, then it is being used else no. This is a fairly simple approach, but the major issue with this approach is that the memory requirements of the index which would be needed to efficiently respond to such queries are directly proportional to the number of usernames.
This is where bloom filters showcase their value. They allow systems to respond to such queries in O(1) space and time.
How does Bloom Filter work?
The bloom filter is a k-bit bitmap that is initially set with all bits as 0. Additionally, n hash functions are needed with a range of 0 to k-1. When a new string is added to the bloom filter, each of the hash functions is used to generate a hash and the corresponding bit is then set to 1 in the bitmap. This will be done for each of the string which is provided as input to the bloom filter.
Here's a diagram that shows how this would work :
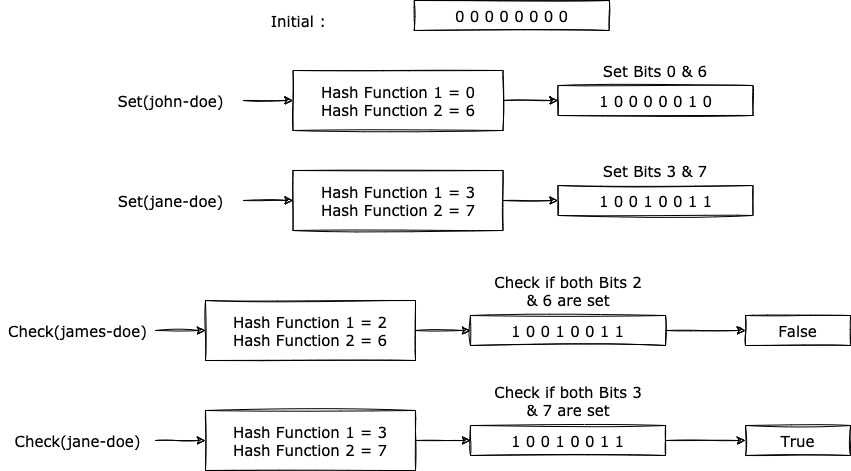
Now, if there is a candidate c that needs to be tested for presence, the same n hash functions will be used to generate a hash and if all the bits are set to 1 already, then it returns that the candidate c might be present in the set. Otherwise, if any one of the bits is set to 0, it returns false.
This approach using bloom filter requires significantly low storage compared to the approach discussed earlier. For example, to store 1 million items with 5 hash function and a probability of 0.01, approximately 1MB of storage is needed. This kind of storage also allows caching of the bloom filter in memory.
There are also other extensions over the bloom filters like Counting Bloom Filter. In the above explanation, only set and check operations were supported. If the use case requires support for delete operation too, then Counting Bloom Filter can be used. In this case, instead of setting bits, integers can be used to represent every bit and the set and delete operation would lead to the addition or deletion of 1 respectively, check function would then check if all hash values are greater than 0 for returning true.
Storage and Accuracy Tradeoff
One of the questions which arise now is why is it unable to determine accurately if a candidate is present in the set. This is because of a well-known issue with hashing: collisions. There can be cases where two candidates c1 and c2 might get the same bits set to 1 and in such scenarios, if c1 was added to the set and c2 is tested for presence, the bloom filter will return a false positive. This is also known as the Bias of the bloom filter.
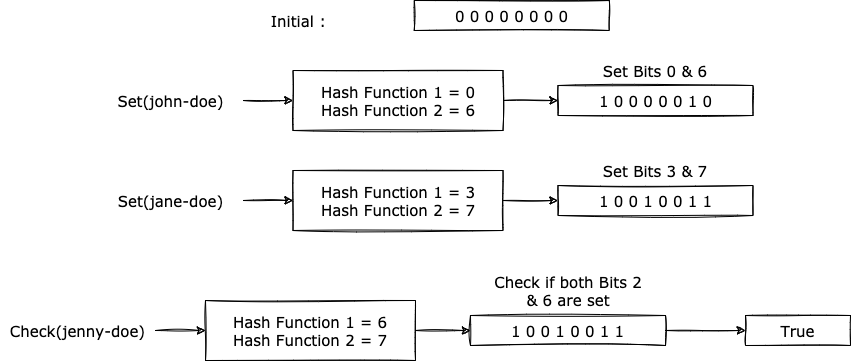
To reduce the probability of such false positives, the bloom filter size should be carefully decided based on the number of expected entries and acceptable collision probabilities. This is a trade-off that needs to be considered while building the system. Here's a tool which can be used to calculate the bitmap size based on the number of items expected and the probability of false positives.
NOTE : Rebalancing is not possible in bloom filters as the history is not stored. Proper estimation of the number of entries expected in future and acceptable probabilities need to be made while using it.
How to use Bloom Filter?
As discussed above, the storage requirements of the bloom filter are very low and overall logic can be easily implemented. However, there are already battle-tested implementations available like Bloom Filter in Google Guava which can be used to keep a host-level bloom filter. Alternatively, if the use case requires a distributed instance, Redis supports it via an extension called Redis Bloom.