

HyperLogLog - Faster Cardinality Estimation
Count Distinct Problem in Computer Science


In the sketching algorithms series, next up is how to solve the count-distinct problem. This problem has numerous applications like finding the number of unique visitors on a website. Let's first clearly define the problem statement :
Count-Distinct problem (also known as Cardinality Estimation) is the problem of finding the number of distinct elements in a data stream consisting of repeated elements.
The naive solution of the problem would require keeping track of all the distinct elements and compare the elements of the stream to this set of distinct elements. The time complexity of this solution would O(1) and space complexity will be O(N) if a hash set is used to implement it.
HyperLogLog
HyperLogLog(HLL) is an algorithm that allows responding to such queries in O(1) time complexity and O(log(log(N)) space complexity. The idea behind the algorithm is based on the probability of having N leading 0s in a bit string. The probability of having N leading zeroes in a bit string is 1/2N or it can be said that in a uniformly distributed data set, 2N elements need to be encountered to find N leading 0s.
Flajolet-Martin Algorithm
If there are N elements in a data set and there is a hash function H(), for each element e in the data set, H(e) is computed. To track the number of distinct elements, store the largest number of leading zeroes encountered in H(e). If the hash function is uniformly distributed then, the number of distinct elements encountered will be approximately 2L, where L is the largest number of leading 0s encountered. This algorithm is called the Flajolet-Martin Algorithm.
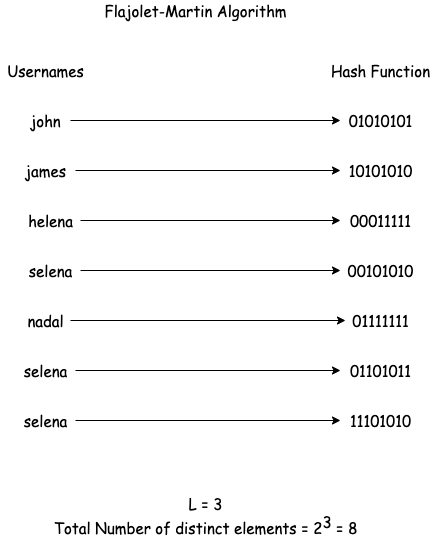
As can be seen in the above diagram, the output of the algorithm was close to the actual number of distinct elements. But it is also evident that if the only element encountered in the stream was helena the output would still have been 8 which would be far from the accurate value.
LogLog and SuperLogLog Algorithm
The approximation above seems to be biased for small data sets, it can be further improved by using multiple hash functions and then using the average of L for each function to compute. Computing multiple hash functions can be computationally expensive, so instead of using multiple hash functions, let's use the first few bits of the hashed output to divide the output into buckets as shown in the below diagram.
 This is the LogLog Algorithm. But as seen in the above example the value is still very high compared to the actual number of elements. In order to further reduce the bias, 70% of the top bucket values can be ignored. This is known as the SuperLogLog algorithm. The output, in this case, would be 11 which is much closer to the output of the LogLog algorithm.
This is the LogLog Algorithm. But as seen in the above example the value is still very high compared to the actual number of elements. In order to further reduce the bias, 70% of the top bucket values can be ignored. This is known as the SuperLogLog algorithm. The output, in this case, would be 11 which is much closer to the output of the LogLog algorithm.
Finally, HyperLogLog
Finally, HyperLogLog attempts to further reduce the bias. It simply replaces the arithmetic mean with the harmonic mean of the values. This is because the harmonic mean is much more immune to outliers as can be seen in the below diagram.

Parallelization
One of the benefits of using HLL is the ease of parallelization it provides. If there are multiple hosts, each host can use the same hash function and number of buckets. In such a case, to merge the results, just take the maximum value of each bucket and apply the above algorithm. The result would be the same as computing everything on a single host.
How to use HyperLogLog?
Redis supports HyperLogLog as a data structure that can be used to count the number of distinct elements. More details can be found here. There is also a Java library called stream-lib which supports HLL operations.